Voynich: the punctuation problem
One issue which has long interested me concerning the Voynich manuscript (VM), and which has not perhaps been researched as much as it should, is what we can call the punctuation problem.
Obviously the script is noteworthy for having no obvious punctuation, which is rare in itself. However, as a linguist what then interests me is how the reader could know where the ‘sense-units’ begin and end? If we assume that we are dealing with a natural underlying language, the reader would have to have signals of some sort, in the absence of punctuation, as to where the sense endings would be, especially on pages containing lengthy chunks of text. Consider this text from f25v. Is it a single sentence? If so, it is quite long. Does it contain any dividers of any sort? Almost certainly, but what and where?

Although historically many scripts had little punctuation, they almost always had instead some form of ‘discourse marker’ to help the reader to follow the writer’s flow of ideas 서문세가 다운로드. An example from classical Arabic, which had very little punctuation, but tended to connect long sentences with ‘and… and’ , is the word ‘hal’, an essentially empty word signifying that the following sense unit was to be read as a question. It had no translatable meaning beyond flagging up the function of the sentence as a question. It is what we term a ‘discourse marker’, no more.
It could be that the Voynich script uses a series of such markers, along with other devices, to flag up to the reader certain aspects of the discourse. In this post I want to consider a number of possible discourse and textual markers in the VM, of different types, which seem to me interesting.
1.  Line breaks: From pages f103 onwards we see many pages in which the ‘sense units’ seem to be clearly demarcated by simple line breaks, with each new sense unit demarcated by a star on a string or a flower Goclean Ad Removal. See e.g.:
https://www.jasondavies.com/voynich/#f103r/0.499/0.501/2.50
This might seem too obvious to mention, but if we assume, as seems likely, that each ‘paragraph’ of these pages represents one ‘sentence’, then closer examination could elucidate some properties of the typical Voynich ‘sentence’, and even its sentence structure.
2.  Specific signs: Some of the the famous ‘gallows’ characters’, in particular those transcribed in the EVA system as ‘p’ and ‘f’ do appear to act as initiating discourse markers, flagging up the start of sections. They are often decorated, which seems to add to the possibility that they are discourse ‘flags’ of some sort.
As Currier noted years ago, “[t]hey ( p , f ) appear 90-95% of the time in the first lines of paragraphs, in some 400 occurrences in one section of the manuscript.â€. This in itself implies that they are being used to indicate or highlight the first line of a text. More to the point they occur 107 times as page initial (93 pages with ‘p’ and 14 with ‘f’). Since it is highly unlikely that the author could find actual words beginning with these letters to start these pages, it is plausible to suggest that the symbols are perhaps semantically empty markers used simply to flag the start of a page or section, just as we use a semantically empty full-stop to indicate the end of a sense unit 워페이스 다운로드.
If you use the wonderful new tool at www.voynichese.com you can see that Currier was largely correct with respect to EVA ‘p’ and ‘f’. However, note that EVA ‘k’ and ‘t’ are far more common and seem not to be limited so much to the first lines, which suggests that they are far more than simple ‘initiating markers’ .
3. Lexical discourse markers: Another possible discourse marker, which could act to indicate to the reader the ways in which ideas link together, could be the most common word in the manuscript, transcribed in EVA as ‘daiin’. In my 2012 paper I suggested that this word might be the equivalent of a comma, or ‘and’. Let me revisit some of that paper here.
My argument started from the last page of the manuscript (116 v), and the analysis offered by Johannes Albus at the Voynich 100 conference in Italy, in which he argued that the text is a recipe in Latin and German, with two words in ‘Voynichese’ Quantum Break. He explained that the text prescribed a way of using Billy Goat’s liver as a remedy for wet rot, a skin condition, and his analysis was supported by numerous examples from contemporary recipes and other sources, as well as by reference to the picture of the goat and liver in the margin. I reproduce the original page here.

Albus’ transcription and gloss is as follows:
Transcription with abbreviations and omissions in square brackets
|
Â
Translation (Johannes Albus)
| Billy goat´s liver for wet rot At the membrane you gave oil, then you bring a lot of the much(?) wax, in a fixed mixture: 9 hands full, 9 morsels (from) the only just double mature … … (two ciphered words), squash it into a paste, then take goat´s milk. |
The fact that the text contains two words in Voychinese is significant, since it means that it was not simply a later addendum by an unrelated scribe, but is linked at least tangentially to the rest of the VM. As such it could serve as a help to its interpretation, for reasons we can now consider.
I won’t consider here the German/Latin aspects here, but if we examine Albus’ interpretation we note that the prescription has a clear structure, starting with the heading on line 1 which indicates the nature of the preparation and also its medicinal use 인생의 회전목마 다운로드. Line 2 and the start of line 3 offer an instruction with verbs in the second person, namely ‘dabas’ (imperfect or future of ‘dare’ to give) and ‘portas’ (present of ‘portare’, to carry), although why the tenses are different is unclear. This is followed in line 3 with further ingredients and quantities to be added, with Line 4 offering the two Voychinese words, followed by further instructions in the form verb + noun.  The words have been transliterated as ‘oror sheey’ (Palmer 2004, http://inamidst.com/voynich/michitonese).
I have suggested in my February 2014 paper that the word transcribed as ‘oror’ could refer to juniper, but what interests me here is the ‘punctuation’.  Note that the text in 116v is divided up into sense units separated by a + symbol. These do not divide words, but larger units of meaning, so for example the words in “an[te] chiton olei dabas in line 2 are not each separated by crosses mfc140.dll 다운로드. It is not always clear to the modern reader why the sense units are separated in this text (e.g. why ‘multas’ and ‘tunc’ form separate units) but what is clear is that the author considered it important to indicate these separations specifically, using a cross, in addition to leaving spaces between each word.
This kind of sense-division on f116v is – I suggest – arguably the same as the function of ‘daiin’ on other pages, such as on f25v reproduced above. Look at the page again with ‘daiin’ highlighted (thanks to www./voynichese.com):

The element ‘daiin’ is repeated not only in the middle of the first four lines, but five more times. Considering the fact that this is the most frequent item in the manuscript as a whole, this frequency was perhaps to be expected, but note that it is never inflected in any way, whereas it follows words beginning with ‘ch’ which clearly do inflect in some way, such as ‘cho’, then ‘chor’ then ‘chol’ and so on.
I suggest that that the most probable function of ‘daiin’, frequent as it is, yet not changing, is as a kind of divider between sense-units, a discourse marker indicating to the reader the sense break expired files. In plainer language, the  function of ‘daiin’ is simple but important – it acts much like the word ‘and’ or a modern comma.
‘Daiin’ might have a literal meaning, but that is fundamentally unimportant in functional terms, since its essential function here seems to be to show the reader where a small sense-unit ends. In some cases it is doubled (as in folio 25v, line 5) perhaps to signal a more substantial sense-break, more like a full-stop. (This doubling occurs 17 times in the manuscript, with one tripling on folio 89r2.). But usually it seems to act as an ‘and’ or comma dividing individual sense units.
If this is so, it goes some way to answering the question posed above about how a reader would break up the text in the absence of any other punctuation marks. ‘Daiin’ gives the reader a clear guide as to how to recognise the start and end of short sense-units.
We can take this further by comparing f25v with the ‘prescription’ as analysed by Albus on f 116v oracle 11g express edition. This is still speculative, of course, but we notice that if we take ‘daiin’ as a sense divider, the resulting structure resembles the prescription analysed by Albus, as follows (transcribed in EVA):
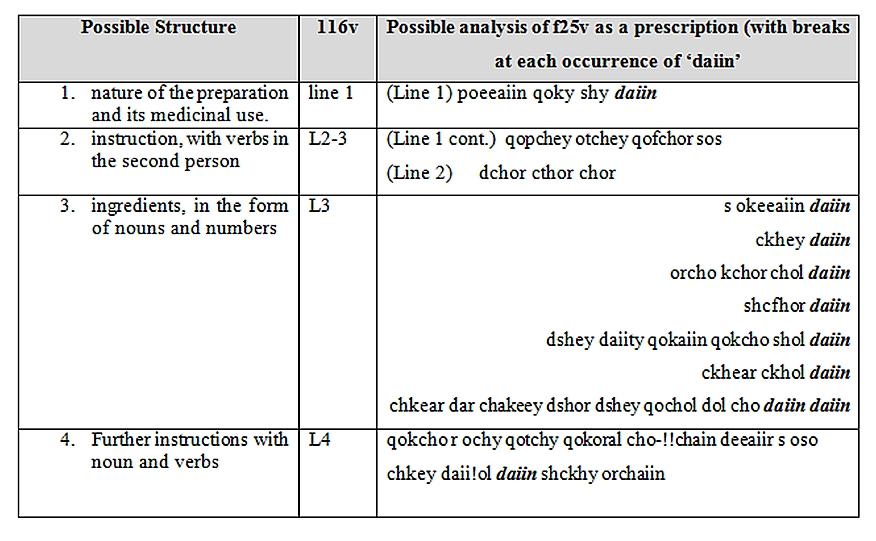
 From Bax 2012
Although this is speculative, it is possible that this text is a prescription, with the high incidence of daiin markers in the middle of the text indicating different ingredients, mirroring the high number of crosses in the middle of f116v.
Observation of the original text suggests that the single character which has been transcribed as ‘s’ (in ‘s okeeaiin’ line 2) does not look like other characters transcribed as ‘s’. but rather resembles the Arabic numeral ‘2’, so it could in fact be a number for a following ingredient. However, this possibility requires more translation of the underlying language in order to evaluate it fully.
4. Modified characters: Returning to the question of punctuation and discourse markers, a fourth way in which the Voynich script might signal divisions between sense-units is through the use of particular characters. I suggested in my Feb 2014 paper that the character transcribed in EVA as ‘m’ might be a variant of the ‘r’ character, varied in order to mark the end of sense unit in some way.
In a recent posting on this forum, Cosmo offered some interesting support for this view, using the new tool at www.voynichese.com. Cosmo said:
Stephen, I think there is strong evidence for your suggestion that the transcribed “m†is a final form of another character – “r†being a good candidate – because of how often it occurs as the last character, particularly in the latter folios Download blackpink toutoou mp3.
http://www.voynichese.com/#/all:m/1229
When “m†occurs within a line, it’s usually at the end of a word, for example:
http://www.voynichese.com/#/f3r/all:m/77
There are a few occurrences of “m†within a word but these are quite infrequent and in some cases unclear.
IMO the consistent usage of “m†as the last character in a block means that it is either an embellished character or an abbreviation. The only question is why it does not occur more often, given how common “r†terminated words are.
For example, see this plot of “r†terminated words in yellow and “m†terminated words in blue:
http://www.voynichese.com/#/exa:-m:cyan/exa:-r/1179“
Naturally I agree ( 🙂 ) and I am most grateful to Cosmo for showing so graphically the way in which the character seems to operate as an end marker.
To conclude the discussion of modified characters acting as discourse markers, it may well be that other characters could also act in this way – for example EVA ‘g’ as a variant of EVA ‘d’:
http://www.voynichese.com/#/all:g/400
However, this would need more research.
To sum up [how about that for a discourse marker], it seems to me that the Voynich manuscript does contain various devices which act as signals to the reader regarding sense unit boundaries xlsm 다운로드. This is to be expected if we are dealing with a  natural language (or indeed a cipher which imitates natural language patterns).
In my view is also a further strong reason why the Voynich could not be a gibberish hoax, but that is a story for another day!
- Posted in: Voynich ♦ Voynich script and language
75 Comments